
Συγγραφείς
Mavrogiorgos, K.; Kiourtis, A.; Mavrogiorgou, A.; Menychtas, A.; Kyriazis, D. Bias in Machine Learning: A Literature Review. Appl. Sci. 2024, 14, 8860. https://doi.org/10.3390/app14198860
Το παρόν άρθρο στοχεύει να πραγματοποιήσει μια αναλυτική βιβλιογραφική ανασκόπηση σχετικά με τη μεροληψία (bias) στη Μηχανική Μάθηση, διερευνώντας τις αντίστοιχες μεθόδους και προσεγγίσεις που έχουν προταθεί για τον εντοπισμό και/ή την αντιμετώπιση της μεροληψίας σε ολόκληρο τον κύκλο ζωής της Μηχανικής Μάθησης. Πιο συγκεκριμένα, στα πλαίσια του συγκεκριμένου άρθρου, ο κύκλος ζωής της Μηχανικής Μάθησης αποτελείται από τρία (3) διακριτά στάδια για τα οποία υπάρχουν συγκεκριμένοι τύποι μεροληψίας: (i) μεροληψία που μπορεί να προέρχεται από τα ίδια τα δεδομένα (δηλαδή, Μεροληψία Δεδομένων – Data Bias), (ii) μεροληψία που προέρχεται από τα μοντέλα Μηχανικής Μάθησης που χρησιμοποιούνται (δηλαδή, Μεροληψία Αλγορίθμου – Algorithm Bias) ή, (iii) μεροληψία από τους μηχανικούς Μηχανικής Μάθησης που αναπτύσσουν ή/και αξιολογούν τα παραγόμενα μοντέλα Μηχανικής Μάθησης (δηλαδή, Μεροληψία Μηχανικού – Engineer Bias). Έχοντας χωρίσει τον κύκλο ζωής της Μηχανικής Μάθησης σε αυτές τις κατηγορίες, εντοπίστηκαν οι τύποι μεροληψίας που μπορεί να εμφανιστούν σε κάθε κατηγορία, γεγονός που αφενός επέτρεψε τον ορισμό των εν λόγω ειδών μεροληψίας και αφετέρου βοήθησε στον εντοπισμό των αντίστοιχων προσεγγίσεων στη βιβλιογραφία που επιτυγχάνουν την αντιμετώπιση των διαφορετικών ειδών μεροληψίας. Μια επισκόπηση των τύπων μεροληψίας που μπορεί να εμφανιστούν σε καθεμία από τις τρεις (3) κατηγορίες φαίνεται στην Εικόνα 1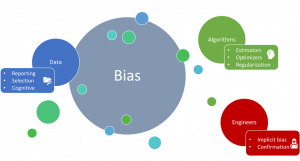
Εικόνα 1. Τύποι μεροληψίας ανά κατηγορία κύκλου ζωής Μηχανικής Μάθησης.
Η μεροληψία δεδομένων σχετίζεται κυρίως με τον τρόπο με τον οποίο επιλέγονται και συλλέγονται τα δεδομένα, καθώς και με τη φύση αυτών. Ως αποτέλεσμα, μπορούν να εντοπιστούν τρεις (3) κατηγορίες μεροληψίας δεδομένων: η μεροληψία αναφοράς (reporting bias), η μεροληψία επιλογής (selection bias) και η γνωστική μεροληψία (cognitive bias). Εκτός από τις προσεγγίσεις που υπάρχουν για την αντιμετώπιση συγκεκριμένων κατηγοριών μεροληψίας δεδομένων, υπάρχουν και κάποιες τεχνικές που μπορούν να χρησιμοποιηθούν ανεξάρτητα του τομέα εφαρμογής. Αυτές οι τεχνικές αναφέρονται κυρίως σε μη ισορροπημένα σύνολα δεδομένων (imbalanced datasets) και στοχεύουν στη μείωση της προκατάληψης στα σύνολα δεδομένων με υποδειγματοληψία (under-sampling) ή υπερδειγματοληψία (over-sampling) [1].
Εκτός από τη μεροληψία που προέρχεται από τα δεδομένα, η μεροληψία μπορεί επίσης να προκύψει λόγω των μοντέλων Μηχανικής Μάθησης που χρησιμοποιούνται. Αρχικά, ο πιο προφανής λόγος που οδηγεί σε μεροληψία είναι η επιλογή ενός αλγορίθμου που δεν είναι κατάλληλος για τη δεδομένη εργασία (π.χ., χρήση ενός γραμμικού μοντέλου για την παροχή πρόβλεψης σε μη γραμμικά δεδομένα). Ένας άλλος λόγος είναι ότι, δεδομένης μιας συγκεκριμένης εργασίας (π.χ. ταξινόμησης), ένας αλγόριθμος μπορεί να έχει καλύτερη απόδοση από άλλους σε μια συγκεκριμένη περίπτωση χρήσης, αλλά να υστερεί σε άλλες περιπτώσεις χρήσης, λόγω της φύσης των αντίστοιχων δεδομένων.
Εκτός από την επιλογή του κατάλληλου αλγορίθμου, θα πρέπει να δίνεται η μέγιστη προσοχή κατά την επιλογή συναρτήσεων βελτιστοποίησης (optimizers) και τεχνικών κανονικοποίησης (regularization), καθώς και τα δύο μπορούν να συμβάλουν σε μεροληπτικές αλγοριθμικές αποφάσεις, ανεξάρτητα από την απουσία ή την παρουσία μεροληψίας στα δεδομένα εκπαίδευσης [2].
Ο τρίτος παράγοντας που μπορεί να επηρεάσει τα μοντέλα Μηχανικής Μάθησης όσον αφορά την εισαγωγή μεροληψίας είναι οι μηχανικοί Μηχανικής Μάθησης που είναι υπεύθυνοι για την εκπαίδευση ή/και την αξιολόγηση τέτοιων μοντέλων. Οι κατασκευαστές μοντέλων Μηχανικής Μάθησης είναι επιρρεπείς σε ένα συγκεκριμένο είδος μεροληψίας το οποίο ονομάζεται implicit bias, στο οποίο εκπαιδεύεται ένα μοντέλο σύμφωνα με τις προσωπικές πεποιθήσεις των μηχανικών οι οποίες ενδέχεται να μην ισχύουν καθολικά [3].
Για να μετριαστεί η μεροληψία κατά την αξιολόγηση των μοντέλων, οι συγγραφείς στο [4] προτείνουν ένα σχέδιο δράσης τριών βημάτων που αποτελείται από στατιστική επικύρωση αποτελεσμάτων, εκπαίδευση ενός εκτιμητή δεδομένων ως μοντέλο ελέγχου και διεξαγωγή αξιολόγησης μοντέλων Μηχανικής Μάθησης από τρίτους. Αυτό το σχέδιο δράσης συνοψίζεται στην Εικόνα 2.
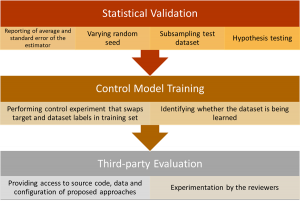
Εικόνα 2. Σχέδιο δράσης για τη μείωση της μεροληψίας κατά την αξιολόγηση των μοντέλων Μηχανικής Μάθησης.
Συμπερασματικά, από όλες τις δημοσιεύσεις που αναλύθηκαν στα πλαίσια αυτού του άρθρου, 39 δημοσιεύσεις ανέλυσαν μεθόδους και τεχνικές για τον εντοπισμό και τον μετριασμό της μεροληψίας δεδομένων, 21 συγκριτικές μελέτες τόνισαν τη σημασία της επιλογής του κατάλληλου εκτιμητή (αλγορίθμου) για την αποφυγή της εισαγωγής περαιτέρω μεροληψίας και 24 συγκριτικές μελέτες ανέλυσαν τον τρόπο με τον οποίο μια τεχνική κανονικοποίησης (regularization) μπορεί να βοηθήσει στη μείωση της αλγοριθμικής μεροληψίας. Όσον αφορά τον τρόπο με τον οποίο μία συνάρτηση βελτιστοποίησης μπορεί να επηρεάσει ένα μοντέλο από την άποψη της μεροληψίας και πώς ένας μηχανικός Μηχανικής Μάθησης μπορεί να εισάγει μεροληψία στο μοντέλο που εκπαιδεύει ή/και αξιολογεί, μόνο εννέα (9) και τρεις (3) μελέτες αντίστοιχα εντοπίστηκαν στη βιβλιογραφία, όπως φαίνεται στην Εικόνα 3.
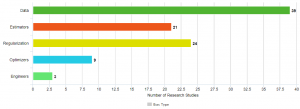
Εικόνα 3. Αριθμός ερευνητικών μελετών ανά τύπο μεροληψίας
Σύμφωνα με το παραπάνω, οι μελλοντικές ερευνητικές προσεγγίσεις θα πρέπει να στοχεύουν (i) να αιτιολογήσουν καλύτερα την επιλογή μίας συγκεκριμένης συνάρτησης βελτιστοποίησης και πώς μπορεί να ελαχιστοποιήσει την μεροληψία σε σύγκριση με άλλες αντίστοιχες συναρτήσεις και (ii) να αξιολογήσουν τις προτεινόμενες προσεγγίσεις τους σύμφωνα με τα κατάλληλα κριτήρια και να προσφέρουν διαφάνεια στα εκπαιδευμένα μοντέλα τους, επιτρέποντας την αξιολόγηση από τρίτους αξιολογητές.
Αναφορές
[1] Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36.
[2] Mehrabi, N.; Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35.
[3] Holroyd, J.; Scaife, R.; Stafford, T. What is implicit bias? Compass 2017, 12, e12437.
[4] Biderman, S.; Scheirer, W.J. Pitfalls in Machine Learning Research: Reexamining the Development Cycle. Available online: https://proceedings.mlr.press/v137/biderman20a